
Why Distributed Systems Outlast Prompt Engineering
Stop fighting the model and start building the rig: Why the future of AI is architectural, not linguistic

We are currently drowning in a surplus of tutorials on “prompt engineering”: the art of coercing a probabilistic model to output valid JSON. This is a transient problem. By 2028, model steering will be handled by the model providers via native constraints or fine-tuned checkpoints. The syntax barrier will dissolve.
What remains is the architectural reality: we are integrating nondeterministic, high-latency, expensive components into deterministic systems.
The Senior Engineer of the future will not be valued for their ability to write a “clever” system prompt. They will be valued for treating an LLM as what it actually is: an unreliable third-party service with high jitter and zero ACID guarantees.
If you want to survive the next cycle, stop optimizing for the prompt. Start optimizing for the partition.
The LLM as a Flaky Microservice
In traditional distributed systems, we strive for idempotency and determinism. f(x) should always equal y.
LLMs introduce a new primitive: the Stochastic Function. f(x) -> y (probability p) f(x) -> z (probability 1-p)
From a systems perspective, an LLM call is functionally identical to a network call to a service with specific, hostile characteristics:
High Latency: Median completion times for reasoning tasks (e.g., GPT-4-class models) often exceed 2,000ms.
Variable Throughput: Token generation rates fluctuate based on provider load (KV-cache evictions, GPU availability).
Non-Zero Failure Rate: Refusals, hallucinations, and structural schema violations are effectively 5xx errors.
Most “AI Engineers” today handle this with retry loops in Python. This is insufficient for production workloads exceeding 100 RPS.
Law of Stochastic Systems: You cannot fix probabilistic failure with deterministic code unless you wrap the probabilistic component in a strict verification envelope.
The Fallacy of “Agentic” Loops
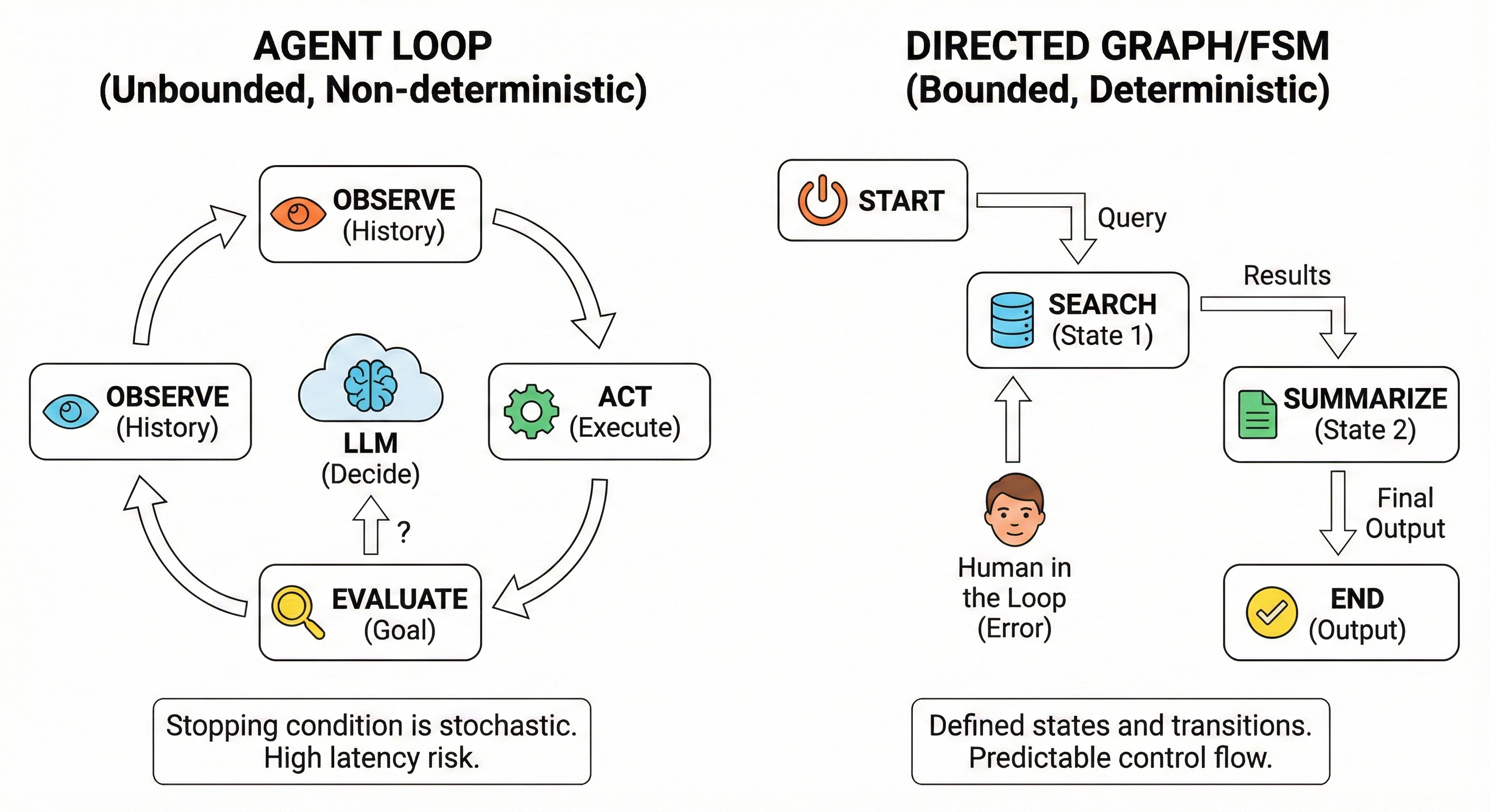
Current “Agent” frameworks encourage a pattern where the LLM decides the control flow.
The Anti-Pattern
Python
# Unbounded Control Flow
while goal_not_met:
next_action = llm.decide(history)
execute(next_action)
This is a distributed systems nightmare. You are creating an unbounded loop where the stopping condition is determined by a stochastic actor.
Cost Risk: Unbounded.
Latency:
O(n)where n is the number of “thoughts.”Debuggability: Zero.
The production-grade architecture replaces these open loops with Finite State Machines (FSMs).
Instead of letting the model hallucinate the next step, the engineer defines a directed graph of valid states. The LLM is restricted to a classification role: it selects the transition edge, but the runtime executes the transition.
This shifts the architecture from “Magic Box” to “Router.” If the LLM fails to select a valid edge, the system defaults to a safe state or escalates to a human—standard circuit-breaker patterns applied to cognition
.
Latency Budgets and Async Orchestration
Embedding a synchronous LLM call in a user-facing blocking request is malpractice.
Consider a standard RAG (Retrieval-Augmented Generation) pipeline:
Embed query: ~50ms
Vector Search (HNSW): ~100ms
Rerank (Cross-Encoder): ~200ms
LLM Generation: ~2,000ms+
Total P50 latency: ~2.35s. Total P99 latency: Can spike to 10s+ if the provider queues requests.
No user waits 10 seconds for a UI update. The solution is not “faster models” (physics limits memory bandwidth). The solution is asynchronous event-driven architecture.
The robust stack looks like this:
Ingest: API Gateway accepts request -> pushes to Kafka/Redpanda. Returns
202 Acceptedwith ajob_id.Process: Worker nodes consume the topic. They handle the stochastic “thinking” time.
Notify: WebSockets or Server-Sent Events (SSE) push the token stream to the client.
We are returning to 2015-era microservices patterns because the compute unit (the GPU inference) has become the bottleneck, much like the spinning disk database was in the past.
Consistency vs. Creativity (The AI CAP Theorem)
We need a revised CAP theorem for AI systems. You can pick two:
Coherence: The output follows instructions and logic perfectly.
Creativity: The output provides novel or varied responses.
Latency: The response is generated in sub-500ms.
Coherence + Creativity: Chain-of-Thought reasoning. You sacrifice Latency.
Latency + Coherence: Caching or smaller, over-fitted models (e.g., Llama-3-8B-Instruct). You sacrifice Creativity.
Architects must map these trade-offs to business requirements. A customer support bot requires Coherence + Latency. A creative writing assistant requires Coherence + Creativity.
Idempotency in Non-Deterministic Flows
What happens when an agent performs a side effect (e.g., UPDATE users SET plan = 'premium') and then the LLM crashes or the network partitions before the confirmation is logged?
If you simply retry the prompt, the LLM might decide to run the tool again.
The solution is transactional idempotency keys. Every tool call generated by the LLM must be hashed and stored. If the system retries, the execution layer checks:
Python
if hash(tool_call) in redis:
return cached_result
This ensures that even if the “brain” (LLM) forgets context and tries to execute the same payment twice, the “body” (Runtime) refuses. This requires deep knowledge of distributed state management, not prompt engineering.
The Evaluation Pipeline is the New Unit Test
Writing unit tests for syntax (assert result == 5) is effectively a solved problem. The human engineer’s job is writing Evals.
An Eval is a statistical unit test. Since f(x) is stochastic, we cannot assert equality. We must assert probability distributions over N runs.
Bad: “Check if the summary is good.”
Good: “Run 100 times. Assert that in >95 cases, the JSON output contains key
order_idand the cosine similarity to the ground truth embedding is >0.85.”
This moves engineering closer to reliability engineering (SRE). You are managing error budgets for logic.
Summary
The “End of Syntax” does not mean the end of complexity. It means the complexity has migrated from the syntax tree to the system architecture.
The engineers who will command the highest compensation in the coming cycle are not the ones who know the magic words to make GPT-5 sing. They are the ones who can build a system that remains robust when GPT-5 inevitably hallucinates, times out, or changes its behavior post-update.
Double down on:
Message Queues (Kafka, NATS)
State Machines (Temporal, durable execution)
Vector Database Internals (Quantization trade-offs, not just “magic search”)
Observability (Tracing stochastic flows)
Let the juniors play with prompts. You build the rig.